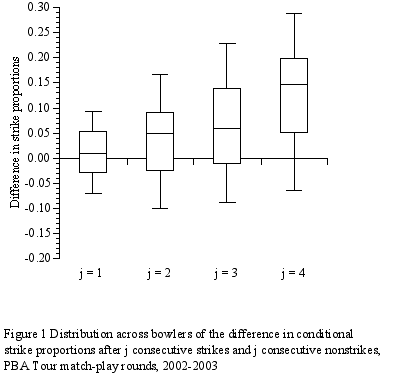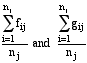
Bowlers’ Hot Hands
Reid Dorsey-Palmateer and Gary Smith
Department of Economics
Pomona College
Claremont, California 91711
gsmith@pomona.edu
909.607.3135
Fax 909.621.8576
contact: Gary Smith, Department of Economics, Pomona College, Claremont, California
91711
Abstract
Gilovich, Vallone, and Tversky’s (1985) analysis of basketball data debunked the common perception that players sometimes have “hot hands.” However, their basketball data do not control for several confounding influences. Our analysis of professional bowling indicates that, for many bowlers, the probability of rolling a strike is not independent of previous outcomes and the number of strikes rolled varies more across games than can be explained by chance alone. For example, most bowlers have a higher strike proportion after j consecutive strikes than after j consecutive nonstrikes, and this difference becomes more pronounced as j increases from 1 to 4.
key words: hot hands, bowling, self-efficacy
* We are very grateful to Walter Ray Williams Jr. for his generous and patient answers to our many questions, and to the referees and (especially) the editor for their exceptionally detailed and helpful suggestions.
Bowlers’ Hot Hands
The binomial model is often applied to athletic endeavors even though the model is surely an imperfect representation of athletic performances. Unlike a fairly flipped coin, athletes compete under varying game conditions and have aches, pains, and other human frailties. A baseball player’s probability of getting a hit depends on the opposing pitcher. A basketball player’s probability of making a basket depends on the location from which the shot is taken. Every athlete’s performance is affected by physical health.
One interesting question is whether athletes’ success probabilities are affected by physical or psychological factors of the sort described by Purvis Short, a professional basketball player: “You’re in a world all your own. It’s hard to describe. But the basket seems so wide. No matter what you do, you know the ball is going to go in.” This quotation prefaces the second of three hot-hands papers based on research by Gilovich, Vallone, and Tversky (Gilovich, Vallone, & Tversky 1985; Tversky & Gilovich 1989a; Tversky & Gilovich 1989b). These papers argue that the common belief that players sometimes get “hot” or “get in a zone” is erroneous, in that memorable performances happen no more often than would be predicted by the binomial model.
We argue that the basketball data used by Gilovich, Vallone, and Tversky have serious flaws and that statistical tests often have little power to detect hot hands. Our analysis of bowling data—a sport largely free of confounding influences—indicates that, for many bowlers, the probability of rolling a strike is not independent of previous outcomes and the number of strikes rolled varies more across games than can be explained by chance alone.
Good Data
The primary data analyzed by Gilovich, Vallone, and Tversky are the shooting accuracy of Philadelphia 76er basketball players during the 1980–1981 season. The probability of making a shot was usually somewhat lower after having made shots than after having missed shots, and the number of runs of hits and misses by individual players across all games and within individual games was slightly larger than would be expected if shots were independent (the opposite of the hot-hands phenomena), though these patterns were seldom statistically persuasive. For example, only one of nine runs tests had a p-value less than 0.05, and this was for a player who had more runs than expected.
Unfortunately, their data do not identify how much time passed between shots. A player’s two successive shots might be taken 30 seconds apart, 5 minutes apart, in different halves of a game, or even in different games. Another problem is that the shots a player chooses to take may be affected by his recent experience. A player who makes several shots may be more willing to take difficult shots than is a player who has been missing shots. In addition, the opposing team may guard a player differently when he is perceived to be hot or cold. Shot selection may also be affected by the score and the number of fouls accumulated by players on both teams.
The hot-hands question asks whether highly skilled and motivated athletes sometimes encounter hot and cold spells that are not due to confounding influences and cannot be easily explained as chance fluctuations about a constant success rate. Smith (2003) examines horseshoe pitching data from the 2000 and 2001 World Championships and finds variations in player performances within games and across games that indicate that success probabilities are not constant. Championship horseshoe data are much cleaner than basketball data in that every pitch is made from the same distance at regular, brief intervals with intense concentration and little or no strategy. Bowling is a sport with similar statistical characteristics. (Remarkably, Walter Ray Williams Jr., is one of the top athletes in both sports, having won six world horseshoe pitching championships and six professional bowling player of the year awards.)
Bowling Data
Bowling lanes are slightly less than 63 feet long and between 41 and 42 inches wide, with gutters on either side to catch balls that fall off the lane. Ten target pins are arranged in a pyramid shape with 60 feet from the start of the lane to the pin at the pyramid tip closest to the bowler.
Each game has 10 frames. In tournament match play, two bowlers use two lanes to compete against each other. One bowler starts on the left lane and the other starts on the right. The player on the left bowls his first frame on the left lane. After that, each bowler (starting with the bowler on the right) bowls two frames, the first on the right lane and the second on the left lane, until the end, when the bowler who went first bowls his tenth frame on the right lane.
The ten pins are reset at the start of each frame. If a bowler knocks all ten pins down on the first throw, this is called a strike. If fewer than ten pins are knocked down, the fallen pins are cleared away and the bowler is given a second chance to hit the remaining pins. If the remaining pins are all knocked down on the second roll, this is called a spare; otherwise it is an open frame.
The bowler’s base score in each frame is equal to the number of pins knocked down in that frame. If there is a spare, the score is increased by number of pins knocked down on the next roll; if there is a strike, the score is increased by number of pins knocked down on the next two rolls. If a spare or strike is rolled in the tenth frame, the bowler is allowed bonus shots (one for a spare and two for a strike) on that lane. A perfect game consists of 12 strikes (ten frames plus two bonus rolls), which gives a score of 300. Professional bowlers roll strikes around 60 percent of the time and average more than 200 points per game.
Professional Bowlers Association (PBA) tournaments start with 120 to 175 bowlers who bowl nine games in the first round. The top 64 from this round advance to the next round and again bowl nine games. The top 32 advance to the match-play rounds and are seeded based on their performance in the first 18 games. The Round of 32 consists of 4-of-7 match-play games between pairs of bowlers, with the winners advancing to the Round of 16, which is 3-of-5 match play. The Round of 8 is also 3-of-5. After the Round of 8, there is the Final Round, in which all games are single-elimination. In most tournaments, there is a wild-card match between the Round-of-8 loser with the best win-loss record in the tournament and the Round-of-8 winner with the worst win-loss record. The wild-card winner gets a place in the semifinals, and the winners of the two semifinal matches compete in the championship match.
In comparison to basketball data, bowling data have many valuable properties for testing violations of the binomial model. Every roll is made from the same distance at regular intervals with intense concentration and no strategic considerations. One possible confounding influence is the condition of the lanes—in particular, the way the lanes are oiled. Oil is usually applied to the first 35-to-45 feet of the lane with the last 15-to-25 feet being dry. The balls gradually wear down the oil and also cause the oil to move down the lane, which can affect a ball’s trajectory. Years ago, the lanes were only oiled once a day and lane conditions could change substantially during the day. Left-handed bowlers were thought to have an advantage because the more numerous right-handed bowlers caused more serious changes in oil conditions on the right side of the lanes. Today, the lanes are stripped and oiled before each round in order to stabilize lane conditions. In PBA match-play rounds a maximum of 7 games are rolled on a lane before it is re-oiled. One indicator of the improved stability of lane conditions is that only 1 of the top 10 money winners in 2002-2003 was left-handed.
Frame, Hughson, and Leach (2003) find evidence of hot hands in bowling using
data from the Final Round of 1994-1998 PBA tournaments. During these years,
the Final Round used a step-ladder format in which the fifth-seeded and fourth-seeded
bowlers played each other, with the winner moving on to play the third-seeded
bowler. The winner of this match played the second-seeded bowler and the winner
of this match played the first-seeded bowler. They find that the winners of
each game won more than 50 percent of their next games, even though they were
playing against higher seeds. This pattern may have something to do with the
higher seeds sitting idly while the lower seeds bowl continuously.
Our data do not involve step-ladder matches and, in addition, we look at each
bowler’s performance within games. Detailed frame-by-frame results for
the 2002-2003 season are available from the PBA (2003) for all match-play games:
the Round of 32, Round of 16, Round of 8, and Final Round.
The Binomial Model
We characterize each bowler’s performance in each frame (or bonus shot) as either a strike or nonstrike, analogous to a coin flip with a success probability that isn’t necessarily 0.50. We use this notation:
pij = player i’s probability of rolling a strike conditional on having just rolled j consecutive strikes
qij = player i’s probability of rolling a strike conditional on having just rolled j consecutive nonstrikes
The binomial model assumes, for each player i, that the trials are independent, so that
| pij = qij = pi for all j |
(1)
|
and that the success probability pi is stationary. In the context of bowling, each player’s chances of rolling a strike would (a) not depend on whether he has rolled strikes or nonstrikes in other frames; and (b) be the same in every frame. The success probability pi can, of course, vary across bowlers.
Independence
One violation of the binomial model that might be interpreted as a hot hand occurs when an athlete’s success probability depends on the outcomes of previous trials; for example, bowler i’s success probability might be higher after a success than after a failure (i1 > qi1) or higher after two consecutive successes than after two consecutive failures (pi2 > qi2). Tversky & Gilovich (1989b) focus on independence as the key assumption disputed by those who believe in hot hands: “Many observers of basketball believe that the probability of hitting a shot is higher following a hit than following a miss, and this conviction is at the heart of the belief in the ‘hot hand.’”
Stationarity
A very different violation of the binomial model that might be interpreted as a hot hand occurs when there is a sustained change in the success probability. For instance, bowler i’s success probability pi might be 0.5 for 30 trials, then abruptly change to 0.7 for 10 trials, and then return to 0.5 for 60 trials. If such changes are unrelated to the outcomes of other trials, the binomial model’s independence assumption is not violated. The hot hand described by Purvis Short seems to involve nonstationarity rather than nonindependence. If hot hands do occur, there may also be cold hands when an athlete’s success probability temporarily falls.
Frame, Hughson, and Leach (2003) show that the runs test used by Gilovich, Vallone, and Tversky has little power to detect nonstationarity in a regime-shifting model in which a player has a specified probability of switching back and forth between hot-shooting and cold-shooting regimes. For instance, a player might always have a 0.25 probability of switching between a hot regime with a 0.6 success probability and a cold regime with a 0.3 success probability.
Wardrop (1999) examines the power of several tests using a different model of nonstationarity. The athlete has a base success probability PB (for example, 0.5). At some random point in 100 Bernoulli trials, the athlete gets hot and the success probability rises to PH for a specified number of trials (for example, PH = 0.8 for 10 trials). When the hot period ends, the athlete’s success probability returns to PB. The binomial model applies during each of the three subperiods in that the outcomes are independent and the success probability is constant within each subperiod. None of the tests Wardrop considers has much power to detect nonstationarity unless PH is much larger than PB.
Wardrop’s model is an appealing representation of the phenomenon described by Purvis Short. We will investigate the power of several tests by using a generalized model in which bowlers have temporary hot and cold spells.
A Simulation Model
Our simulation model involves a single bowler who has temporary hot and cold spells. In our model, the bowler’s probability of rolling a strike is usually PB, but during every 7 games there are randomly determined, nonoverlapping 10-frame hot and cold periods with respective success probabilities PH and PC. We use PB = 0.60, which is approximately equal to the overall 0.59 strike proportion in our data set, and two pairs of hot and cold probabilities: PH = 0.7, PC = 0.5 and PH = 0.8, PC = 0.4. For comparison, Walter Ray Williams Jr., the top bowler in 2002-2003, had a 0.66 strike proportion in his match-play games. For a PBA match-play bowler, a change in the strike probability from 0.6 to 0.4 or 0.8 seems enormous, but perhaps not impossible.
In each game the bowler has a 10% chance that the tenth frame will be open (neither a strike or a spare), which is the proportion of the time this event occurred in our data.
We consider three tests which we illustrate with the following 1-game simulation, where the result in each frame is characterized as either a strike s or nonstrike n:
| n | n | s | s | n | s | s | s | s | s | n |
The first test is based on the conditional strike frequencies: a tabulation of the number of strikes and nonstrikes immediately after a strike or nonstrike. In our example,
|
current frame
|
|||
|
previous frame
|
strike
|
nonstrike
|
total
|
|
strike
|
5
|
2
|
7
|
|
nonstrike
|
2
|
1
|
3
|
|
total
|
7
|
3
|
10
|
Fisher’s exact test uses the hypergeometric distribution to test the null hypothesis that the conditional strike probability does not depend on whether there was a strike or nonstrike in the previous frame; that is, Equation 1 with j = 1. Here with 10 previous frames, 7 of which contain strikes, the exact probability that 7 current frames chosen at random contain 5 or more strikes is 0.708.
The second test is a nonparametric test based on the number of runs, where a run is a sequence of successive strikes or nonstrikes. (Gilovich, Vallone, and Tversky report both a runs test and a serial correlation test, but Wardrop shows that in practice these two tests give virtually identical results.) For a fixed number of successes and failures, Stevens (1939) gives the formula for calculating the exact probability that the number of runs would be equal to or smaller than the value actually observed (indicating the presence of hot and cold streaks) for the null hypothesis that the given number of successes and failures are randomly arranged. In our example, there are 7 strikes, 4 nonstrikes, and 5 runs. If these 7 strikes and 4 nonstrikes were randomly arranged, the exact (one-sided) probability that there would be 5 or fewer runs is 0.333.
The third test is a nonparametric test based on the length of the longest run. For a fixed number of successes and failures, Bateman (1948) gives the formula for calculating the exact probability that the length of the longest run would be as long as actually observed for the null hypothesis that the given number of successes and failures are randomly arranged. In our example, the length of the longest run is equal to 5 strikes in a row. If the 7 strikes and 4 nonstrikes were randomly arranged, the exact (one-sided) probability that there would be at least one run of length 5 or longer is 0.227.
The 7-game simulation model was replicated 10 million times for each of the three scenarios: PH = PC = 0.6; PH = 0.7, PC = 0.5; and PH = 0.8, PC = 0.4. The three statistical tests were applied to the data generated by each simulation and a tabulation was made of the frequencies with which the three statistical tests yielded p-values less than or equal to 0.05. Results are shown in Table 1 for tests based on the first game, the first 3 games, the first 5 games, and all 7 games in each simulation. The large number of simulations allows the reporting of the p-value proportions to three decimal places. If the success probability is around 0.05, the simulation standard error for the sample success proportion is approximately equal to (0.05(0.95)/10,000,000)0.5 = 0.00007.
The case PH = PC = 0.6 corresponds to the null hypothesis that the success probability is constant. Because discrete data yield discontinuous p-values, the chances of obtaining a p-value less than 0.05 is less—sometimes substantially less—than 0.05. The values PH = 0.7, PC = 0.5 and PH = 0.8, PC = 0.4 represent substantial changes in a bowler’s strike probability, yet the frequency with which the null hypothesis is rejected at the 5% level is not much higher than when the null hypothesis is true (and is usually less than 5%!). These simulations make it especially pertinent to remember that the failure of a hot-hands statistical test to reject the null hypothesis does not prove that the binomial model is true.
Tests of Many Athletes
If the binomial model is not appropriate, it may be because the performances of a few unique athletes are dramatically inconsistent with the model, or it may be because many (if not most) athletes experience hot and cold spells. Hot-hands studies generally examine the performance of several athletes and our interpretation of the results must be tempered by the number of tests conducted. For example, if each test has a 0.05 probability of Type I error, it won’t be surprising if 5 of 100 independent tests have p-values less than 0.05. On the other hand, it may be noteworthy if 10 tests have p-values less than 0.05. In order to gauge the results of many tests, we can calculate a “p-value for the p-values” by testing the null hypothesis that, on each test, there is a 0.05 probability of obtaining a p-value less than or equal to 0.05:
| H0: P[p-value 0.05] = 0.05 |
(2)
|
If there are n independent tests, each with 0.05 success probability, the binomial distribution gives the probability that x or more tests would have p-values less than 0.05. For example, with n = 100 and x = 10, the p-value for the p-values is P[x Ž 10] = 0.0282.
Our simulation model demonstrates that the interpretation of a count of the number of p-values below a prespecified level is complicated by the fact that discrete data yield discontinuous p-values. Consider a game with 7 strikes and 4 nonstrikes. If strike and nonstrike frames are independent, the probability of at least one run of 6 or more frames is 0.076 and the probability of at least one run of 7 or more frames is 0.015: the probability of a p-value less than 0.05 is 0.015.
Now suppose that we look at 100 independent games with 7 strikes and 4 nonstrikes and find 5 games with at least one run of 7 or more. At first glance, it seems unsurprising that 5 of 100 tests have p-values less than 0.05. However, if the probability of a p-value less than 0.05 is actually 0.015, the binomial distribution tells us that, in 100 independent tests each with a 0.015 success probability, there is only a 0.0177 probability of 5 or more successes. The p-value for our p-values is 0.0177; 5 of 100 games with at least one run of 7 or more is noteworthy!
Matters are considerably more complicated than this because the number of strikes and nonstrikes and the probability of a p-value less than 0.05 vary from game to game. Sometimes the probability of a p-value less than 0.05 is 0.015; sometimes it is 0.025. Another complication is that the number of strikes and nonstrikes may be such that the number of runs cannot possibly be statistically persuasive because the probability of a p-value less than 0.05 is 0. For example, if a bowler rolls all strikes, the statistical fact that such data will always yield a longest run of 12 means that a test based on the length of the longest run has a p-value of 1.0. Now suppose we have 100 tests of which 20 cannot possibly have p-values less than 0.05. If we find that 8 of 100 tests have p-values less than 0.05, it is really 8 of the 80 tests that can have p-values less than 0.05.
Thus, if the null hypothesis is true, we will tend to find that fewer than 5% of the test results have p-values less than 0.05. A corollary is that, if the null hypothesis is false, we may find that not many more (or even fewer) than 5% of the tests have p-values less than 0.05.
Analysis
Frame-by-frame data from the 2002-2003 PBA match-play rounds are used to investigate whether bowling data are consistent with the binomial model’s assumptions of independence and stationarity. Because the success probability can vary across bowlers, we analyze data for individual bowlers and we will often use a p-value for the p-values to determine whether more bowlers get hot hands than would be predicted by the binomial model.
Independence
The binomial model assumes that a player’s probability of rolling a strike is independent of whether he rolled strikes or nonstrikes previously. Table 2 summarizes data based on the frequencies with which bowlers rolled strikes immediately after having rolled 1-to-4 consecutive strikes or 1-to-4 consecutive nonstrikes. All of these data are from within games; we do not consider whether the first roll of a game is influenced by the last roll of the previous game. For each category, we only consider bowlers who had at least 10 observations in both situations. For example, there were 43 different bowlers who had at least 10 occasions in which they bowled after rolling 4 consecutive strikes and also had at least 10 occasions in which they bowled after rolling 4 consecutive nonstrikes.
The first data row in Table 2 shows nj, the number of bowlers who had least 10 opportunities to bowl immediately following j consecutive strikes and also had least 10 opportunities to bowl immediately following j consecutive nonstrikes. The second and third data rows are the unweighted averages across bowlers of the conditional strike proportions after j consecutive strikes and j consecutive nonstrikes:
where
fij = player i’s strike proportion immediately following j consecutive strikes.
gij = player i’s strike proportion immediately following j consecutive nonstrikes.
Because these are unweighted averages, they are not affected by the fact that good bowlers have more opportunities to bowl after strikes than after nonstrikes. These unweighted averages can help us assess whether the observed differences in conditional strike proportions are substantial. For example, a 0.612 strike probability (the 83rd percentile for unconditional strike proportions among PBA match-play bowlers) is much better than a 0.492 strike probability (the 17th percentile).
The fourth and fifth data rows show the number of bowlers who had a higher strike proportion after j consecutive strikes than after j consecutive nonstrikes. For example, 34 of the 43 bowlers who had at least 10 opportunities to bowl after 4 consecutive strikes and after 4 consecutive nonstrikes had a higher strike proportion after 4 consecutive strikes. The higher conditional strike proportions after strikes are evidently not due to a few bowlers getting very hot, but rather to many bowlers having hot and cold spells.
Table 2 shows the p-values for two statistical tests described below of the null hypothesis that Equation 1 holds simultaneously for all bowlers; that is, each bowler’s conditional success probability is the same after j consecutive strikes and after j consecutive nonstrikes. The conditional success probabilities can of course depend on j and vary across bowlers.
Matched-Pair Difference in Conditional Strike Proportions. The first statistical test is the Wilcoxon (1945) signed-rank test for paired differences. The paired difference for each bowler is the difference between his strike proportion after j strikes and after j nonstrikes: dij = fij - gij. For example, Paul Fleming had 123 opportunities to bowl after having bowled 4 consecutive strikes and he rolled a strike on 84 of these occasions (fi4 = 0.683); he also had 37 opportunities to bowl after having bowled 4 consecutive nonstrikes and he rolled a strike on 16 of these occasions (gi4 = 0.432). His paired difference is di4 = 0.683 - 0.432 = 0.251. For j = 4, the mean difference for all 43 bowlers is
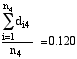
The means of the paired differences increase as j increases from 1 to 4: 0.011, 0.036, 0.060, and 0.120, respectively.
Figure 1 shows four side-by-side boxplots for the values of dij across bowlers. For each value of j, the Wilcoxon test ranks the absolute values of the paired differences across bowlers, signs the ranks based on whether the difference is positive or negative, and sums these signed ranks Rij. With more than 40 observations, the probability distribution of the Wilcoxon test statistic
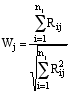 |
(3)
|
is well approximated by the normal distribution. As shown in Table 2, the p-values are less than 0.05, especially for j > 1.
Number of Bowlers with Fisher Exact p < 0.05. The second test statistic is based on the application of Fisher’s exact test to each bowler’s conditional success frequencies after j consecutive strikes and after j consecutive nonstrikes. Unlike the Wilcoxon test, this test uses data on the number of observations for each bowler.
Using the example of Paul Fleming again, this bowler had 123 opportunities to bowl after having bowled 4 consecutive strikes and he rolled a strike on 84 of these occasions; he also had 37 opportunities to bowl after having bowled 4 consecutive nonstrikes and he rolled a strike on 16 of these occasions:
|
current frame
|
|||
|
previous frame
|
strike
|
nonstrike
|
total
|
|
strike
|
84
|
39
|
123
|
|
nonstrike
|
16
|
21
|
37
|
|
total
|
100
|
60
|
160
|
Using the hypergeometric distribution, Fisher’s exact test gives a p-value of 0.0056.
For each value of j, we count the number of bowlers who had a Fisher exact p-value less than 0.05 with a higher success proportion after strikes than after nonstrikes. For j = 4, for example, Table 2 shows that of the 43 bowlers who had at least 10 opportunities to bowl after 4 consecutive strikes and after 4 consecutive nonstrikes, 7 (16 percent) had differences in their strike frequencies in these situations that yielded a p-value less than 0.05 with a higher strike proportion after 4 consecutive strikes.
The p-value for the p-values shown in Table 2 is for a test of the null hypothesis that each bowler has a 0.05 probability of having a p-value less than 0.05 with a higher strike proportion after j strikes:
H0: P[p-value 0.05 with fij > gij] = 0.05
The binomial distribution gives the probability, were the null hypothesis true, that the number of bowlers who have a p-value less than 0.05 with a higher strike proportion after j strikes would be as large or larger than actually observed. For example, for the n = 43 bowlers who had at least 10 opportunities to bowl after 4 consecutive strikes and after 4 consecutive nonstrikes, the binomial probability of having 7 or more such cases is P[x Ž 7] = 0.005. This p-value for the p-values is quite low and even more impressive if we recall that the underlying p-values are discontinuous.
Individual bowlers. We can also identify the individual bowlers whose strike proportions were most inconsistent with the independence assumption. Table 3 shows four such bowlers. As with the 2 X 2 table for Paul Fleming discussed earlier, the p-values are based on the hypergeometric distribution for testing the null hypothesis that each bowler’s conditional success probability is the same after j consecutive strikes and after j consecutive nonstrikes. To put these p-values into perspective, we again need to consider the number of bowlers tested. For example, of the 111 bowlers who, on at least 10 occasions, bowled after 2 consecutive strikes and after 2 consecutive nonstrikes, the probability that 2 or more bowlers would have p-values less than 0.0005 is 0.0015. For each of these four bowlers, the observed differences in strike proportions following consecutive strikes and nonstrikes are substantial.
Stationarity
One type of evidence of nonstationary success probabilities would be if a bowler’s performance fluctuated from game to game within a round more than would be expected if bowling were a Bernoulli process with constant success probability.
Table 4 shows two examples from the 2002-2003 PBA World Championship, the last tournament of the season. In his four “Round of 16” games, Walter Ray Williams Jr. had an overall strike proportion of 0.739. If his chances of rolling a strike were the same in each game, the expected value of the number of strikes in each game would be 0.739 multiplied by the number of frames in that game. In practice, his actual strike proportions in these 4 games varied dramatically from 0.364 to 1.000. The chi-square statistic uses the squared differences between the observed values Oi and the expected values Ei to gauge whether these differences are improbably large:
|
(4)
|
The exact p-value for this chi-square statistic can be computed using the multivariate hypergeometric distribution (Agresti and Wackerly 1977). For the first example in Table 4, the exact p-value is .001. In his four “Round of 8” games in this tournament, in contrast, Walter Ray’s overall strike proportion was 0.66, with game strike proportions that varied from 0.50 to 0.75. In this case, the p-value is an unpersuasive 0.631.
We computed p-values for all bowlers in all rounds in this way and tabulated the number of p-values that were less than 0.05. The null hypothesis is given by Equation 2—for each test there is a 0.05 probability that the p-value will be less than 0.05. If there are n independent tests and x tests have p-values less than 0.05, the binomial distribution gives the p-value for the p-values—the probability that x or more tests would have p-values less than 0.05. Here, 70 of 1001 tests had p-values less than 0.05. If the null hypothesis were true, the probability that 70 or more of n = 1001 tests would have p-values less than 0.05 is P[x Ž 70] = 0.0036. Although 70 is only 7 percent of 1001 tests, remember that we are using discrete data for individual tests that have little power to detect plausible violations of the binomial model.
An alternative way of looking at these data is to tabulate the number of tests with p-values less than 0.50. If the null hypothesis were true, we would expect about half the tests to have p-values less than 0.5 and half to have p-values larger than 0.5. In practice, 555 of these 1001 tests had p-values less than 0.5. If the p-values were equally likely to be above and below 0.5, the binomial distribution gives a 0.0003 probability that 555 or more p-values would be below 0.5.
Perfect games. A perfect game of 12 consecutive strikes might be viewed as the ultimate hot hand. Yet, tests applied to such a game in isolation can provide no evidence of a hot hand. A game with all strikes always has undefined conditional proportions after nonstrikes, one run, and a longest run of 12. Instead, we compare the total number of perfect games with the number that might be expected if the binomial model applied.
There were 19 perfect games during match play on the 2002-2003 PBA tour. To determine whether this is more or fewer than might be expected, we did 100,000 simulations with each bowler rolling the number of match-play games that he actually rolled on the tour and having a constant strike probability equal to his actual strike proportion during his match-play games. In these simulations, there were an average of 11.7 perfect games and only 3.1% of the simulations had 19 or more perfect games.
Another way to look at the perfect games is to consider that there were a total of 42 occasions in which bowlers began games with 10 strikes in 10 frames, needing strikes in the two bonus rolls to complete a perfect game. Interestingly, the overall strike proportion for these 10-strike bowlers during the 2002-2003 season was 0.560, somewhat lower than the 0.590 strike proportion for all bowlers. If we assume that each of these 42 bowlers had a strike probability equal to his own season strike proportion, the probability that 19 or more of these 42 bowlers would roll the two strikes needed to complete a perfect game is 0.032.
Discussion
Gilovich, Vallone, and Tversky (1985, 1989a, 1989b) argue that the performance of professional basketball players does not provide persuasive evidence of hot hands. Their studies have been widely cited, leading many to believe that the perception by fans and players that athletes sometimes get hot is an example of how people erroneously see patterns in random data.
One challenge in looking for statistical evidence of hot hands is that most athletic contests involve many confounding influences. Another hurdle is that statistical tests with relatively few observations generally have little power unless there are large violations of the binomial model’s assumptions.
Bowling data are relatively clean in that, unlike basketball data, every roll in a game is from the same distance and made at regular, brief intervals. In our analysis of PBA match-play data, we find, unlike Gilovich, Vallone, and Tversky, evidence that individual success probabilities for many bowlers are neither independent of previous outcomes or constant across games. In particular, many bowlers tend to do better after having done well and their performances tend to vary more across games than would be predicted by chance.
For example, most bowlers have a higher strike proportion after j consecutive
strikes than after j consecutive nonstrikes, and this difference becomes more
pronounced as j increases from 1 to 4. For j = 4, 34 of the 43 bowlers had a
higher strike proportion after 4 consecutive strikes than after 4 consecutive
nonstrikes and, looking at all 43 matched-pair differences in strike proportions,
the average paired difference is 0.120 and the p-value is less than 0.001. In
addition, applying Fisher’s exact test to the conditional strike frequencies
for these 43 bowlers, 16 percent had individual p-values less than 0.05.
The inherent nature of basketball games and many other athletic contests makes
it very difficult to obtain data clean enough for conclusive tests of the hot
hands theory. However, it seems unlikely that professional bowlers are the only
athletes to experience hot hands.
References
Agresti, A., & Wackerly, D. (1977). Some exact conditional tests of independence for r x c cross-classification tables. Psychometrika, 42, 111-125.
Bateman, G. (1948). On the power function of the longest run as a test for randomness in a sequence of alternatives. Biometrika, 35, 97–112.
Frame, D., Hughson, E. & Leach, J.C. (2003). Runs, regimes, and rationality: The hot hand strikes back. Working paper.
Gilovich, T., Vallone, R., & Tversky, A. (1985). The hot hand in basketball: On the misperception of random sequences. Cognitive Psychology, 17, 295–314.
PBA Tour. (n.d.). Retrieved March 15, 2003, from http://www.pbatour.com.
Smith, G. (2003). Horseshoe pitchers’ hot hands. Psychonomic Bulletin & Review, 10, 753-758.
Stevens, W. L. (1939), Distribution of groups in a sequence of alternatives, Annals of Eugenics, 9, 10–17.
Tversky, A., & Gilovich, T. (1989a). The cold facts about the “hot hand” in basketball. Chance, 2, 16–21.
Tversky, A., & Gilovich, T. (1989b). The “hot hand”: Statistical reality or cognitive illusion? Chance, 2, 31–34.
Wardrop, R.L. (1999). Statistical tests for the hot-hand in basketball in a controlled setting. Working paper.
Wilcoxon, F. (1945). Individual Comparisons by Ranking Methods. Biometrics, 1, 80-83.
Table 1
Simulation Results. Proportion of p-Values Less than 0.05 When
the 0.6 Success Probability
Increases to PH = 0.6 + D for 10 Frames and Falls to PC
= 0.6 – D for 10 Frames in Every 7 Games
|
1 Game
|
3 Games
|
5 Games
|
7 Games
|
|||||||||||||
|
D
|
0.0
|
0.1
|
0.2
|
0.0
|
0.1
|
0.2
|
0.0
|
0.1
|
0.2
|
0.0
|
0.1
|
0.2
|
||||
| Fisher’s Exact Test |
.009
|
.009
|
.009
|
.019 |
.019
|
.019
|
.025
|
.025
|
.026
|
.028
|
.028
|
.030
|
||||
| Number of Runs |
.025
|
.025
|
.025
|
.034
|
.035
|
.037
|
.038
|
.040
|
.045
|
.040
|
.042
|
.051
|
||||
| Longest Run |
.016
|
.016
|
.016
|
.018
|
.019
|
.021
|
.018
|
.019
|
.025
|
.019
|
.021
|
.030
|
||||
p-values are based on these tests:
Fisher’s exact test: compares the conditional strike and nonstrike frequencies after a strike or nonstrike in the preceding frame
number of runs: exact probability that the number of runs would be at least as small as actually observed if the observed strikes and nonstrikes were arranged randomly.
longest runs: exact probability that the length of the longest run would be at least as long as actually observed if the observed strikes and nonstrikes were arranged randomly.
Table 2
Strike Proportions Immediately Following Consecutive Strikes
or Nonstrikes,
PBA Tour match-play rounds, 2002-2003
|
Number of Consecutive Strikes/Nonstrikes
|
|||||||||
|
1
|
2
|
3
|
4
|
||||||
| Number of Bowlers |
134
|
111
|
81
|
43
|
|||||
|
Unweighted Mean Conditional Strike Proportion
|
|||||||||
| after strikes |
.571
|
.582
|
.593
|
.612
|
|||||
| after nonstrikes |
.560
|
.546
|
.533
|
.492
|
|||||
| Number of Bowlers with Higher Conditional Strike Proportion | |||||||||
| after strikes |
80
|
77
|
59
|
34
|
|||||
| after nonstrikes |
54
|
33
|
22
|
9
|
|||||
| Wilcoxon Signed Rank Test for Paired Difference in Conditional Strike Proportions | |||||||||
| mean difference |
.011
|
.036
|
.060
|
.120
|
|||||
| p-value |
.020
|
.000
|
.000
|
.000
|
|||||
| Binomial Test for Number of Bowlers with Fisher Exact p < 0.05 | |||||||||
| number of bowlers |
10
|
13
|
8
|
7
|
|||||
| p-value for the p-values |
.135
|
.004
|
.050
|
.005
|
|||||
Table 3
Four Bowlers’ Strike Proportions Immediately Following Consecutive Strikes or Nonstrikes
| Number of Consecutive Strikes/NonStrikes | |||||
|
1
|
2
|
3
|
4
|
||
| Total Number of Bowlers |
134
|
111
|
81
|
43
|
|
| Paul Fleming | |||||
| strike frequency after strikes |
.636
|
.627
|
.649
|
.683
|
|
| strike frequency after nonstrikes |
.559
|
.463
|
.423
|
.432
|
|
| p value |
.0106
|
.0005
|
.0007
|
.0056
|
|
| Bryon Smith | |||||
| strike frequency after strikes |
.636
|
.665
|
.695
|
.684
|
|
| strike frequency after nonstrikes |
.540
|
.432
|
.436
|
.400
|
|
| p value |
.0156
|
.0002
|
.0032
|
.0197
|
|
| Mike DeVaney | |||||
| strike frequency after strikes |
.651
|
.637
|
.667
|
.632
|
|
| strike frequency after nonstrikes |
.505
|
.435
|
.452
|
.421
|
|
| p value |
.0011
|
.0015
|
.0134
|
.0830
|
|
| Dave D’Entremont | |||||
| strike frequency after strikes |
.643
|
.622
|
.634
|
.610
|
|
| strike frequency after nonstrikes |
.530
|
.463
|
.512
|
.529
|
|
| p value |
.0027
|
.0055
|
.1025
|
.3624
|
|
The p-values are based on Fisher’s exact test comparing each
bowler’s conditional strike and nonstrike frequencies after a strike or
nonstrike in the preceding frame.
Table 4
Walter Ray Williams, Jr’s Strikes by Game in the Round
of 16 and Round of 8
at the 2002-2003 PBA World Championship, with Expected Values in Parentheses
|
Round
|
Game
|
Accuracy
|
Strikes
|
Nonstrikes
|
Total
|
P-value
|
|
16
|
1
|
.364
|
4 (8.1)
|
7 (2.9)
|
11
|
|
|
2
|
.917
|
11 (8.9)
|
1 (3.1)
|
12
|
||
|
3
|
.636
|
7 (8.1)
|
4 (2.9)
|
11
|
||
|
4
|
1.000
|
12 (8.9)
|
0 (3.1)
|
12
|
||
|
Total
|
.739
|
34
|
12
|
46
|
0.0018
|
|
|
8
|
1
|
.727
|
8 (7.3)
|
3 (3.7)
|
11
|
|
|
2
|
.750
|
9 (7.9)
|
3 (4.1)
|
12
|
||
|
3
|
.500
|
6 (7.9)
|
6 (4.1)
|
12
|
||
|
4
|
.667
|
8 (7.9)
|
4 (4.1)
|
12
|
||
|
Total
|
.660
|
31
|
16
|
47
|
.5672
|
The p-value is the exact probability for the chi-square statistic based on the squared differences between the observed and expected values.