Regression to the Mean and Football Wagers
Marcus Lee and Gary Smith
Department of Economics
Pomona College
Claremont, California 91711
gsmith@pomona.edu
Abstract
Football performances are an imperfect measure of abilities, and consequently exaggerate differences in abilities. The skills of those football teams that perform the best and the worst are not really that far from average; thus their future performances regress to the mean. Betting data indicate that gamblers do not fully account for this regression.
key words: pointspreads, regression to mean, betting odds
Regression to the Mean and Football Wagers
The performance of a professional football team depends on its ability and also on chance—unpredictable variations in the opponent’s play calling, the players’ health, the officiating, and even the proverbial bounces of the football. When such chance events make observed performance an imperfect measure of ability, observed differences in performance tend to exaggerate underlying differences in abilities. Performances consequently regress toward the mean, in that those teams that perform the best at any point in time typically do not perform as well subsequently.
If gamblers understand this statistical phenomenon, the betting lines set by bookmakers whose objective is to equalize the dollars wagered on opposing bets will implicitly take regression to the mean into account. If, on the other hand, gamblers do not appreciate regression to the mean sufficiently, they will overreact to successes and failures, cause betting lines to do likewise, and create profitable betting opportunities.
Regression Toward the Mean
Regression occurs in a variety of contexts (Schmittlein, 1989). For instance, any two variables with equal variances and a joint normal distribution with correlation between 0 and 1 exhibit regression to the mean (Maddala, 1992). Suppose, for example, that height and weight are bivariate normal and have been scaled to have equal variances. Because height and weight are imperfectly correlated, the tallest people are not the heaviest (weights regress to the mean) and the heaviest are not the tallest (heights regress to the mean). To say that height and weight regress to the mean relative to each other is equivalent to saying that height and weight are positively but imperfectly correlated.
Similarly, the imperfect correlation between objective probabilities and personal subjective probabilities implies that those events with the most extreme objective probabilities have less extreme subjective probabilities and that those events with the most extreme subjective probabilities have less extreme objective probabilities (Erev, Wallsten, & Budescu, 1994). Thus, when the revision-of-opinion literature uses objective probabilities to predict subjective probabilities, subjective probabilities regress to the mean, indicating underconfidence (Slovic & Lichtenstein, 1971); when the calibration literature uses subjective probabilities to predict objective probabilities, objective probabilities regress to the mean, indicating overconfidence (Yates, 1990).
Another context for regression to the mean is exemplified by the educational testing literature where observed test scores are an imperfect measure of a latent trait (the “true score”), which can be interpreted as the expected value of a person’s test score (Lord & Novick, 1968). The difference between the observed score and the true score is the error score. If the error score is not always zero, observed scores that are bivariate normal with equal variances regress toward the mean. Those who score highest on a test are most likely to have had positive error scores that put their observed scores farther from the mean than are their abilities. Those with the highest scores as 7-year-olds will, on average, have scores closer to the mean as 8-year-olds.
In sports, observed performance depends on chance as well as skill and is consequently an imperfect measure of skill. For example, of all major league baseball players since 1900 who had batting averages of .300 or higher in at least 50 times at bat in any season, 80% had lower batting averages the following season; of all pitchers who had earned run averages of 3.00 or lower in at least 25 innings in any season, 80% had higher earned run averages the following season (Schall & Smith, 2000).
Are We Aware of Regression to the Mean?
Regression toward the mean is a pervasive but subtle statistical principle that is often misunderstood or insufficiently appreciated. Regression to the mean should not be confused with the fallacious law of averages, which states that an unusual number of successes must be balanced by failures; for example, that a winning football team is due for a loss. After the New England Patriots beat the Miami Dolphins in the 1986 National Football League playoffs, a Los Angeles Times columnist (Oates, 1986) wrote that “the Dolphins were basically losing to the law of averages. They had won 18 straight from New England in that stadium.”
The correct regression principle implies that the best-performing teams will, on average, continue to perform above average, but not as well as they had previously since their stellar performances were more likely affected by good fortune than bad. The fact that Miami had beaten New England 18 straight times did not mean that they would always beat New England; their perfect record exaggerated how much better they were than New England. On the other hand, each victory did not increase the probability that they would lose the next time they played.
Regression to the mean in scores should not be misinterpreted as implying that abilities are converging to the mean. The correct conclusion is that those teams that are currently the most successful generally aren’t as talented as their lofty records suggest. Most have had more good luck than bad, causing their performance to overstate their ability. When their performances regress toward the mean, their place at the top will be taken by other teams that perform above their ability.
There is well-established evidence that most people are blind to regression to the mean in a variety of contexts (Campbell, 1969; Kahneman & Tversky, 1973). One of the most memorable examples occurred in the 1930s when Horace Secrist, a statistics professor at the Northwestern University, wrote a book with the provocative title The Triumph of Mediocrity in Business (Secrist, 1933). Secrist had found that businesses with exceptional profits in any given year tend to have smaller profits the following year, while firms with very low profits generally do somewhat better the next year. From this evidence he concluded that strong companies were getting weaker, and the weak stronger, so that soon all would be mediocre. The president of the American Statistical Association wrote an extremely enthusiastic review of this book (King, 1934); another statistician pointed out that Secrist had been fooled by regression to the mean (Hotelling, 1933; see also Friedman, 1992). Yet a Nobel laureate (Sharpe, 1985) and other prominent economists (Fama & French, 2000) have redone Secrist’s research with no apparent recognition of the implications of regression to the mean for their analysis.
Kahneman and Tversky (1973) note that regression to the mean is all around us—from scores on consecutive tests to the intelligence of spouses—yet most seem blind to it. People are surprised when regression occurs and invent fanciful theories to explain it. If pilots who excel in a training session do not do as well in the next session, it is evidently because the flight instructors praised them for doing well. If bright wives have duller husbands, it is evidently because smart women prefer to marry men who are not as smart. Kahneman and Tversky argue that this blind spot is due to people’s reliance on a representativeness heuristic: “the predicted outcome should be maximally representative of the input and, hence, the value of the outcome variable should be as extreme as the value of the input variable.”
Sports fans seem to underestimate the role of chance in athletic contests. They consequently interpret fluctuations in performance as largely fluctuations in skill. Thus the inevitable runs in random sequences of events are thought to be meaningful hot and cold streaks (Gilovich, Vallone, & Tversky, 1985). Similarly, when outstanding performances regress downward to the mean, fans attribute it to a Cy Young Award jinx, rookie-of-the-year jinx, or Sports Illustrated cover jinx. When poor performances regress upward to the mean, it is because the players changed socks or tugged their ears.
If sports bettors do not appreciate fully that chance events make outcomes an imperfect measure of abilities, they will think that those doing very well and those doing poorly will both continue doing this well and poorly, overlooking the statistical fact that the former have undoubtedly had more than their share of good luck and the latter more than their share of bad luck. They will be too optimistic about successful teams and too pessimistic about unsuccessful ones. Bettors who are aware of regression will adjust their wagers accordingly. Our question is whether they do.
A Model
We can think of a team’s ability A as the expected value of its average margin of victory if it were to play every other team. A team with an ability of 0 is a truly average team that would, on average, score as many points as it allows. For simplicity, we do not complicate our model with home-field considerations or the possibility that a team may play better against some teams than others—as neither of these complications affects our conclusions. Betting lines presumably take these factors into account; our question is whether betting lines fully account for regression to the mean.
If Team i has ability Ai and Team j has ability Aj, we assume that the expected value of the margin of victory if Team i plays Team j is the relative ability Xij = Ai – Aj. The actual margin of victory Yij in a single game between these two teams differs from relative ability by an independent and identically distributed error term e:
| Yij = Xij + eij |
(1)
|
Looking at games involving a variety of teams, there is a distribution of relative abilities X and scores Y. If e is independent of X, then the variance of Y is equal to the variance of X plus the variance of e, and is therefore larger than the variance of X:
![]()
Thus the variance of scores is larger than the variance of relative abilities. A large win, for example, typically overstates the difference in abilities.
The correlation between scores and relative abilities depends on the standard deviation of X relative to the standard deviation of Y:
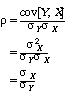 |
(2)
|
If the standard deviation of e were 0, Y and X would be perfectly correlated; as the standard deviation of e becomes infinitely large, the correlation between Y and X approaches 0. This is equivalent to the classical test theory model where the relative ability X is the true score, the actual margin of victory Y is the observed score, and the squared correlation coefficient r2 is the test’s reliability.
If we had data on either absolute or relative ability, we could use Equation 1 to make unbiased predictions of each game’s score. However, we are interested in the reverse question: using game scores to predict abilities. If we use a large sample to estimate
| X = a + bY + u |
(3)
|
by ordinary least squares, the slope will be very close to
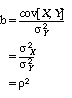
and the intercept will be
![]()
Thus the predicted deviation of a team’s relative ability from the mean relative ability is a fraction of the deviation of this team’s score from the mean score:
![]()
The squared correlation between scores and ability should be used to shrink each team’s predicted ability toward the mean.
In a large sample, the mean of e will almost certainly be close to 0, so that the mean score will almost certainly be very close to the mean relative ability. Therefore, we can also write
|
(4)
|
Predicted relative ability is a weighted average of the score and the mean score, using the squared performance correlation coefficient as the weight. In classical test theory, this is Kelley’s equation (Kelley, 1947).
A Bayesian Interpretation
Recognizing that the error term represents the cumulative effects of a great many omitted variables and appealing to the central limit theorem, we assume that the performance error term e is normally distributed with mean 0 and standard deviation se. A convenient conjugate prior for relative ability X for a specific game is provided by a normal distribution with mean m0 and standard deviation s0. The mean of the posterior distribution for X is then
|
(5)
|
Thus the posterior mean is partway between the game score and our prior mean; in other words, when estimating relative abilities, we should shrink the game score toward our prior mean for relative abilities.
If we had no information about individual teams other than the current game scores, we might set the prior mean for any game equal to the mean relative ability and set the prior standard deviation equal to the standard deviation of abilities. If so, Equation 5 becomes equivalent to Equation 4:
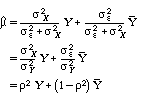
Beating the Pointspread (Or the Total Line)
Football bettors say that, “It doesn’t matter whether a team wins or loses, but whether it beats the spread.” The pointspread set by bookmakers (“bookies”) is a prediction of the margin of victory in a game. Table 1 shows three examples. In its first week of the 2000 National Football League season, Minnesota was a 4-point favorite to beat Chicago. Bettors who picked Minnesota would win their bets if Minnesota won by more than 4 points; those who picked Chicago would win their bets if Chicago won or if Minnesota won by fewer than 4 points.
There is another popular wager called the total line (or “over/under”) that relates not to which team wins and by how much, but to the total number of points scored by both teams. In the Minnesota-Chicago game, those who picked “over” would win if the total score was greater than 47.5; those who picked “under” win if the total was less than 47.5. If the favorite wins by an amount exactly equal to the pointspread or if the total score is exactly equal to the total line (which is impossible with fractional lines), this is called a “push” and the bettors generally get their money back. In the Minnesota-Chicago game, those who picked Chicago and those who chose over won their bets.
Typically, for every $11 wagered by a bettor, the bookmaker wagers $10. Bookies do not want their profits to depend on the outcome of the game. Their objective is to set the pointspread to equalize the number of dollars wagered on each team and to set the total line to equalize the number of dollars wagered over and under. If they achieve this objective, then the losers pay the winners $10 and pay the bookmaker $1, no matter how the game turns out. This $1 profit (the “vigorish”) presumably compensates bookmakers for making a market and for the risk they bear that the pointspread or total line may be set incorrectly.
If a bettor will either win $10 or lose $11, the probability P of winning a bet has to be greater than 0.5238 for the expected value of the payoff to be positive: ($10)P + (–$11)(1 – P) > 0 if P > 11/21 = 0.5238.
Bookies can adjust the pointspread or total line if there is a betting imbalance, but the new values only apply to new wagers. Suppose, to take a ridiculously extreme example, a bookmaker sets the total line at 50 and $1 million is bet under and nothing over; the bookmaker reduces the total line to 40 and now $1 million is bet over and nothing under. If the total score turns out to be below 40 or above 50, the bookmaker is okay; but if the score is between 40 and 50, the bookmaker loses all bets. Clearly, it would have been better to set the line initially at 45, or whatever number would have equalized the wagers over and under.
Bookies attempt to take into account all of the factors that bettors take into account: player strengths and weaknesses, injuries, home-field advantage, historic rivalries. If bookmakers are aware of systematic bettor irrationalities, they will also take these into account. For example, if gamblers are inclined to bet on the Green Bay Packers for sentimental reasons, bookmakers will set the pointspread as if Green Bay is a better team than it really is. If, objectively, the expected value of the Packers’ margin of victory against a certain opponent is 3 points, bookmakers might make the Packers a 5-point favorite in order to equalize the dollars wagered for and against the Packers. The “smart money” will bet against the Packers and win more than half the time. Similarly, if bettors tend to overestimate the total number of points that will be scored, the total line will be set higher than its expected value in order to equalize the under and over bets; the smart money will bet under. On the other hand, bookmakers must be wary of setting betting lines that reflect the biases of naive gamblers but create financially ruinous opportunities for smart money gamblers (Bruce & Johnson, 2000).
Predictions of football scores have many desirable characteristics that have been identified as helpful for producing successful forecasts—including substantial situational similarities, ample forecasting experience, and rapid feedback (Murphy & Brown, 1985; Shanteau, 1992). These characteristics may explain why bookmakers are so successful in setting accurate betting lines. The situation for gamblers is quite different in that those who are lured into making wagers may do so precisely because they are poor forecasters and overestimate their confidence. If the subjective betting lines set by bookmakers are close to the observed relative frequencies, gamblers who believe that their wagers have positive expected values must be mistaken.
There will be room for smart gamblers to make money if naive investors bias betting lines. However, bookies cannot survive unless most people who choose to gamble make wagers with negative expected values. The 5 percent vigorish gives bookies a cushion for making modest misjudgments, but the substantial financial penalties for larger errors assures that inept bookies will be driven out of business. The fact that gambling is a zero-sum game implies that the profits bookies make must be at the expense of bettors.
Gamblers might not learn from their experiences about regression to the mean because it is a subtle concept that eludes even graduate students in psychology (Kahneman & Tversky, 1973) and because gamblers interpret their winning bets as a confirmation of their skill and system, but explain away their losses as flukes and near-wins (Gilovich, 1983).
A Betting Strategy
The setting of betting odds is a complex weighting of many factors—all but one of which we will assume are weighted correctly. Our strategy is based on the simple presumption that a blindness to regression toward the mean causes gamblers and/or bookies to overrate successful teams and to underrate unsuccessful ones. Since betting lines are intended to equalize the dollars wagered on opposing bets, these lines will reflect this blindness, at least within the 5% cushion provided by vigorish. It would be quite surprising if the bias were much larger than this as it would provide opportunities for sophisticated gamblers to bankrupt bookies.
When a team beats the pointspread, one possible explanation is that the team’s relative ability is better than previously believed; we should consequently revise upward our estimate of the team’s ability. Another factor to consider is chance. The regression-to-the-mean argument suggests that the amount by which a team beats the spread is an overestimate of how much better it is than we had previously estimated. If bettors do not fully appreciate regression to the mean, they will think too highly of the team and make the pointspread too high the next week (this team will be too big a favorite). If so, it may be profitable to bet against teams that beat the pointspread and in favor of teams that do not.
Because gamblers have memories, we will keep track of each team’s cumulative record against its pointspreads. We restart this cumulative tabulation each season because of the large number of personnel changes between seasons. Our strategy is to bet in every game against whichever team has done the best against its pointspreads. This strategy does not require an explicit comparison of the teams’ estimated abilities with the pointspread. We simply assume that the bettors push the spread too high for teams that have been the most successful in beating the spread.
Our initial hypothesis was that bettors are influenced by the number of points by which a team beats the spread, and that we should consequently base our bets on the cumulative points by which teams are over or under the spread. If Team i has beaten its spreads by si points, we ceteris paribus bet si dollars against Team i; if si is negative, we bet si dollars in favor of Team i. If Team 1 is playing Team 2, and s1 – s2 is positive, we bet s1 – s2 on Team 2; if is s1 – s2 is negative, we bet s2 – s1 on Team 1. After determining these tentative wagers on every game that week, we scale all of the wagers up or down, as needed, to make the total amount bet each week equal to $1000.
As an example, consider the game between Minnesota and Miami in the second week of the 2000 season, As shown in Table 1, Minnesota had been a 4-point favorite the week before in its game against Chicago and won by 3 points. Because Minnesota is now 1 point under the spread for the 2000 season, we are inclined to bet $1 on Minnesota, hoping that its failure to beat the spread will make other betters, on average, too pessimistic about its chances against Miami. In its first-week game, Miami had been a 3-point favorite over Seattle, and won by 23 points. Because Miami is now 20 points over the spread, we would bet $20 against Miami. On balance then, wanting to bet $1 on Minnesota and $20 against Miami, we bet $21 on Minnesota. After scaling this week’s bets so that the total amount wagered is $1000, we bet $93.33 on Minnesota. As it turned out, Minnesota was a 3-point favorite and won by 6 points, giving us a $93.33 win.
A referee suggested not constraining the weekly bets to be $1000 and also basing the wagers on the the net number of times a team has beaten the spread rather than the cumulative net points by which a team has beaten the spread. Let si equal the number of times that Team i has beaten its spread minus the number of times Team i has not covered its spread, ignoring pushes. If s1 – s2 is positive, we bet s1 – s2 on Team 2; if is s1 – s2 is negative, we bet s2 – s1 on Team 1. For the Minnesota-Miami game in the second week of the 2000 season, Minnesota was net one game under and Miami was one game over; so we bet $2 on Minnesota.
The Total Line
Now consider wagering on whether the combined scores of the two teams will be over or under the total line set by bookmakers. The regression-to-the-mean argument suggests that in a game that goes over the line, the teams are likely to have experienced good luck in scoring points and/or bad luck on defense. If bettors do not fully appreciate the fact that chance factors most likely played a role in the game going over the line, they will make the total lines for these teams too high in subsequent weeks. If so, it may be profitable to bet that teams that have been going over the line will go under the line. Again, this argument does not require an explicit comparison of offensive or defensive abilities with the total line, only knowledge about whether the two teams have been going over or under the total line in previous weeks.
Our initial hypothesis was again that bettors are influenced by the cumulative amount by which teams are over or under the line. If, in previous weeks, Team i has played in games that cumulatively went over the line by ti points, we will ceteris paribus bet ti dollars that this week’s games involving Team i will go under. Our total bet on a game involving Teams 1 and 2 will be the absolute value of t1 + t2 to go under if t1 + t2 is positive or to go over if t1 + t2 is negative.
In the Minnesota-Miami game played in the second week of the 2000 season, the total line was 41. Table 1 shows that, the week before, the total line in the Minnesota-Chicago game had been 47.5, and the total score (30 + 27 = 57) was 9.5 points over—causing us to want to bet $9.50 that Minnesota will go under the next week. In the Miami-Seattle game, the total line had been 36, and the total score (23 + 0 = 23) was 13 points under—making us want to bet 13 dollars that Miami will go over in the second week. Overall, we would bet $3.50 that Minnesota-Miami will go over. To make the total amount wagered this week equal to $1000, we increase the bet to $13.06, which we lost when the total score (13 + 7 = 20) was under 41.
Following the referee suggestion, we also examined a strategy with ti = number of times Team i has been in games that went over minus the number of times Team i has been in games that went under. In a game between Teams 1 and 2, we bet the absolute value of t1 + t2 to go under if t1 + t2 is positive or to go over if t1 + t2 is negative. For the Minnesota-Miami game in the second week of the 2000 season, Minnesota was net one game over and Miami was one game under; so we didn’t bet.
Data
The Gold Sheet (2001) has betting odds and results for all National Football League games from 1993 through 2000; the Football Insider (2001) has similar data for 1995 through 2000. The data are virtually identical with an occasional half-point difference in the quoted pointspread or total line. Competing bookmakers generally offer nearly identical pointspreads and betting lines; otherwise, gamblers will pick and choose where to place their wagers, undermining each bookmaker’s attempt to equalize the number of dollars wagered on each side of a bet. We used the Gold Sheet data for all regular season games; we did not analyze postseason games since these are played by selected teams at a higher level of intensity with somewhat different objectives. In regular season games, teams are encouraged to score as many points as possible, since net points are part of the tie-breaker system to determine qualification, seeding, and home field for post-season games. Post-season games tend to be played more conservatively since one loss eliminates a team and the margin of victory is unimportant.
Table 2 provides some summary statistics for pointspreads. The number of times the favorite has gone over or under the spread excludes “pick-em” games with a zero pointspread. The average pointspreads and actual margins are from the standpoint of the team favored to win the game. The standard deviations and correlation coefficients are from the standpoint of the home team. The total number of times that the favorite has beaten the spread is remarkably close to the number of times it has not. The total-line data in Table 3 show that the average total score has been slightly above the average total line, but that the number of games over and under are nearly equal. The correlations between total lines and total scores are smaller than the correlations between pointspreads and margins of victory.
The least squares line for predicting the margin of victory from the pointspread is Y = 0.92 + 0.46X; the least squares equation for predicting the total score from the total line is Y = 5.88 + 0.88X. The slope coefficients being less than 1 are consistent with regression to the mean. For a game in which the pointspread is one point above the average pointspread, the margin of victory is predicted to be 0.46 points above the average margin of victory. For a game with a total line one point above the average total line, the total score is predicted to be 0.88 points above the average total score.
Equation 2 states that the standard deviation of abilities should equal the standard deviation of performance multiplied by the correlation between ability and performance. For the pointspread data in Table 2, the overall observed correlation and standard deviation of the total score imply a standard deviation of ability equal to 0.40(14.05) = 5.62, which is 8 percent less than the 6.10 standard deviation of the pointspread. For the total-line data in Table 3, the overall observed correlation and standard deviation of the total score imply a standard deviation of ability equal to 0.25(14.11) = 3.53, which is 9 percent less than the 3.89 standard deviation of the total line. The fact that both standard deviations of betting lines are larger than the implied standard deviations of abilities suggest that the gamblers do not take regression to the mean into account fully.
To implement our betting strategy, we begin betting during the second week of each season, using each team’s cumulative performance in previous weeks to determine the values of si and ti. If a team has a bye during the first week of the season, we set si = ti = 0 for its first game.
Results
Table 4 shows a summary of the results of wagers based on the cumulative points a team has been over or under its spreads or lines. Overall, the strategy won 52.05% of the pointspread wagers and 50.52% of the total line wagers. Wagering $11 against the bookie’s $10, the pointspread wagers had a net profit equal to 3.73% of the total dollars wagered and the total line bets had a net loss of 2.24%. Using the binomial distribution to test the null hypothesis that the probability of making a winning wager is 0.50, the probability of picking this many or more winners in 1733 games is 0.046 and the probability of picking this many or more winners in 1742 games is 0.342.
Table 5 shows a summary of the results of wagers based on the cumulative number of games that a team has been over or under its spreads or lines. This strategy won 52.87% of the pointspread wagers (with a 5.96% net profit) and 53.27% of the total line wagers (with a 4.25% net profit). If the probability of making a winning wager is 0.50, the probability of picking so many winners in 1445 games is 0.016 and the probability of picking so many winners in 1451 games is .007.
Our strategy is based on the hypothesis that gamblers underestimate the role of chance in determining football scores. Logically, this myopia will be most exploitable when teams have performed unusually well or poorly. If one team has cumulatively beaten its spreads by 2 points (or on two occasions) and the opposing team has done the same, there is no reason to suppose that bettors are too optimistic about either team. If the second team had beaten its spreads by only one point (or in only one game), we might argue that bettors will be slightly too optimistic about the first team and we should consequently bet against it. However, this excess optimism is so slight that it should not bias the pointspread much and consequently not create an especially profitable betting opportunity. The slight bias is likely to be overwhelmed by the randomness in game scores. This argument suggests modifying our strategy by setting a cutoff: we won’t bet on a game unless the absolute value of (s1 – s2) or (t1 + t2) is greater than the cutoff. Tables 6 and 7 show the results with cutoffs ranging from 0 to 10. The use of cutoffs generally increases the winning percentage and the profit—supporting the idea that our strategy works because bettors are excessively influenced by unexpectedly strong or weak performances.
Logically, the pointspread and total-line strategies are essentially independent wagers; empirically, the correlation between the pointspread wager outcome and the total-line wager outcome is –0.0436 using cumulative points and –0.0017 using cumulative games. Assuming these to be independent tests, we can multiply the two p values in order to calculate the probability that both tests would show such large deviations from the expected number of winning bets if there is only a 0.50 probability of making a winning bet. These joint p values range from 0.004 to 0.016 for the cumulative-points strategy and from 0.00009 to 0.020 for the cumulative-games strategy.
Another referee suggested that we investigate whether the success of this strategy is due to gamblers’ blindness to regression to the mean or to their overweighting of recent information. These ideas overlap since a regression blindness will cause people to place too much importance on recent information. Nonetheless, some insight into this issue might be provided by comparing the success of a strategy that is based solely on the results of the most recent game with a strategy (like ours) that considers results from several earlier weeks.
We consequently redid all of our calculations using backward horizons of 1 to 15 games (each team plays 16 games). For example, with a backward horizon of four games, we assume that gamblers look back no more than four games. The second week of the season, they look back one game; the third week, they look back two games; after the fourth week, they look back four games.
Figures 1 and 2 show the results. For the cumulative-points wagers, all of the pointspread predictions and all but two of the total-line predictions were right more than half the time. The most successful pointspread strategy was based on a backward horizon of eight games (53.21 percent correct, p = 0.0041); the most successful total-line strategy was based on a backward horizon of four games (51.75 percent correct, p = 0.0752). For the cumulative-games wagers, all of the total-line predictions and all but two of the pointspread predictions were right more than half the time. The most successful pointspread strategy was based on a backward horizon of thirteen games (53.16 percent correct, p = 0.0085); the most successful total-line strategy was based on a backward horizon of thirteen games (53.37 percent correct, p = 0.0054).
For the issue raised here, we observe that strategies based just on the most recent game were relatively unsuccessful, suggesting that the success of our strategy is due not to a myopic overweighting of recent information but rather to an underappreciation of regression to the mean. A reasonable explanation for why cumulative performances over several games bias betting lines is that gamblers look back several weeks when deciding how to bet, but do not appreciate fully the fact that successful and unsuccessful performances most likely overstate skill differences.
The relatively low correlations between total scores and total lines suggest that regression to the mean is more pronounced than with pointspreads. If bettors are equally influenced by total line and pointspread outcomes, it might be expected that total lines would offer more profitable opportunities—yet the pointspread lines are the more profitable. One explanation is that bettors may discount total scores, not because of their awareness of regression to the mean, but because they know of the ambiguities in interpreting total scores. Consider the Minnesota-Chicago game in the first week of the 2000 season. The total score of 57 was 9.5 points over the total line of 47.5. What should betters infer from this result when Minnesota plays Miami in the second week of the 2000 season? Minnesota-Chicago may have gone over the line because Minnesota has a better offense or a weaker defense than previously believed, suggesting a high score in the subsequent Minnesota-Miami game. Or Minnesota-Chicago may have gone over the line because Chicago has a better offense or a weaker defense than previously believed, which is irrelevant to the Minnesota-Miami game. If Minnesota-Miami betters discount the Minnesota-Chicago score heavily because of these ambiguities, there may be little room left to exploit their blindness to regression toward the mean.
At the suggestion of a referee, a similar analysis was done for all National Basketball Association (NBA) games during the seasons 1993-94 through 2000-01. The results are similar to those for football wagers. For example, using the results of the most recent game, the points strategy won 50.80% of the pointspread wagers (p = 0.0667) and 50.51% of the total line wagers (p = 0.1744), while the games strategy won 51.33% of the pointspread wagers (p = 0.0318) and 50.62% of the total line wagers (p = 0.1952). Assuming the pointspread and total line wagers to be independent tests, the joint p values are 0.0116 for the points strategy and 0.0062 for the games strategy.
Summary
Data from 1993 through 2000 on two very different kinds of football wagers—pointspread and total line—indicate that gamblers do not take regression to the mean into account fully. A strategy of betting against teams that have done relatively well against their pointspreads (in either cumulative points or games) would have been profitable for a variety of cutoffs for placing a bet, taking into account the bookie’s 5 percent vigorish. A strategy of betting that teams that have been going over or under their total lines will not continue doing so would have been profitable using cumulative games, but not using cumulative points.
The p values are generally less than 0.05 for the pointspread bets, but not for the total line wagers. If these two quite different tests are independent, this evidence is even more statistically persuasive that gamblers do not appreciate fully the implications of regression toward the mean.
References
Andreassen, P., & Kraus, S. (1988). Judgmental prediction by extrapolation. Unpublished discussion paper. Harvard University.
Bruce, A. C., & Johnson, J. (2000). Investigating the roots of the favourite-longshot bias: An analysis of decision-making by supply and demand side agents in parallel betting markets. Journal of Behavioral Decision Making, 13, 413–430.
Erev, I., Wallsten, T. S., & Budescu, D. V. (1994). Simultaneous over- and underconfidence: The role of error in judgment processes. Psychological Review, 101, 519–527.
Fama, E. F., & French, K. R. (2000). Forecasting profitability and earnings. Journal of Business, 73, 161–175.
The football insider. (n.d.). Retrieved March 15, 2001, from http://www.footballinsider.com/
Friedman, M. (1992). Do old fallacies ever die? Journal of Economic Literature, 30, 2129-2132.
Gilovich, T. (1983). Biased evaluation and persistence in gambling. Journal of Personality and Social Psychology, 44, 1110-1126.
Gilovich, T., Vallone, R., & Tversky, A. (1985). The hot hand in basketball: On the misperception of random sequences. Cognitive Psychology, 17, 295–314.
The gold sheet. (n.d.). Retrieved March 15, 2001, from http://www.goldsheet.com/
Hotelling, H. (1933). Review of The Triumph of Mediocrity in Business. Journal of the American Statistical Association, 28, 463–465; Secrist and
Hotelling debated this further in the 1934 volume of this journal, 196–199.
Kahneman, D., & Tversky, A. (1973). On the psychology of prediction. Psychological Review, 80, 237–251.
Kelley, T. L., (1947). Fundamentals of Statistics. Cambridge, MA: Harvard University, 409.
King, W. I. (1934). Review of The Triumph of Mediocrity in Business by Secrist H. Journal of Political Economy, 42, 398–400.
Lord, F. M., & Novick, M. R. (1968). Statistical theory of mental test scores. Reading, MA: Addison-Wesley.
Maddala, G. S. (1992). Introduction to econometrics (2nd ed.). New York: Macmillan, 104–106.
Murphy, A. H., & Brown, B. G. (1985). A comparative evaluation of objective and subjective weather forecasts in the United States. In G. Wright (Ed.), Behavioral decision making (pp. 329–359). New York: Plenum Press.
Oates, B. (1986, January 13). Bears didn’t have to do much to win this one. Los Angeles Times.
Schall, E. M., & Smith, G. (2000). Do baseball players regress toward the mean? The American Statistician, 54, 231–235.
Schmittlein, D. C. (1989). Surprising inferences from unsurprising observations: Do conditional expectations really regress to the mean? The American Statistician, 43, 176–183.
Secrist, H. (1933). Triumph of mediocrity in business. Chicago: Bureau of Business Research, Northwestern University.
Shanteau, J. (1992). Competence in experts: The role of task characteristics. Organizational Behavior and Human Decision Processes, 43, 252–256.
Sharpe, W. F. (1985). Investments (3rd ed.). Englewood Cliffs, N. J.: Prentice-Hall, 430.
Slovic, P., & Lichtenstein, S. (1971). Comparison of Bayesian and regression approaches to the study of information processing in judgment. Organizational Behavior and Human Performance, 6, 649–743.
Tversky, A., & Kahneman, D. (1982). Evidential impact of base rates. In D. Kahneman, P. Slovic, & A. Tversky (Eds.), Judgment under uncertainty: Heuristics and biases (pp. 153–160). Cambridge: Cambridge University Press.
Yates, J. F. (1990). Judgment and decision making. Englewood Cliffs, NJ: Prentice-Hall.
Table 1 Three Betting Lines in
2000
|
Date
|
Favorite
|
Underdog
|
Pointspread
|
Total Line
|
Winner
|
Score
|
|
9/3
|
Minnesota
|
Chicago
|
4
|
47.5
|
Minnesota
|
30-27
|
|
9/3
|
Miami
|
Seattle
|
3
|
36
|
Miami
|
23-0
|
|
9/10
|
Minnesota
|
Miami
|
3
|
41
|
Minnesota
|
13-7
|
Table 2 Pointspreads and Outcomes
|
Favorite
|
Pointspreads
|
Actual Margin
|
||||||
|
Number |
Over
|
Under
|
Mean
|
SD
|
Mean
|
SD
|
Correlation
|
|
|
1993
|
224
|
102
|
113
|
6.07
|
6.60
|
4.75
|
14.34
|
0.39
|
|
1994
|
224
|
100
|
116
|
5.20
|
5.60
|
3.94
|
13.51
|
0.41
|
|
1995
|
240
|
114
|
120
|
5.73
|
6.35
|
4.62
|
13.47
|
0.38
|
|
1996
|
240
|
128
|
106
|
5.48
|
5.72
|
5.28
|
14.01
|
0.39
|
|
1997
|
240
|
102
|
120
|
5.42
|
5.64
|
4.52
|
14.22
|
0.35
|
|
1998
|
240
|
127
|
100
|
5.73
|
6.28
|
6.87
|
14.13
|
0.49
|
|
1999
|
248
|
124
|
114
|
5.51
|
6.05
|
4.21
|
13.96
|
0.31
|
|
2000
|
248
|
115
|
125
|
5.85
|
6.48
|
5.57
|
14.70
|
0.46
|
|
1993-2000
|
1904
|
912
|
914
|
5.60
|
6.10
|
4.98
|
14.05
|
0.40
|
Table 3 Total Lines and Outcomes
|
Score
|
Total Line
|
Total Score
|
||||||
|
Number |
Over
|
Under
|
Mean
|
SD
|
Mean
|
SD
|
Correlation
|
|
|
1993
|
224
|
106
|
114
|
36.98
|
3.26
|
37.42
|
13.95
|
0.15
|
|
1994
|
224
|
107
|
113
|
39.28
|
4.03
|
40.43
|
14.28
|
0.19
|
|
1995
|
240
|
128
|
105
|
40.57
|
3.24
|
42.97
|
14.20
|
0.05
|
|
1996
|
240
|
116
|
119
|
40.45
|
2.70
|
40.85
|
12.70
|
0.15
|
|
1997
|
240
|
116
|
122
|
40.81
|
2.95
|
41.49
|
13.72
|
0.13
|
|
1998
|
240
|
121
|
115
|
40.85
|
3.73
|
42.53
|
14.00
|
0.32
|
|
1999
|
248
|
122
|
120
|
39.95
|
4.26
|
41.71
|
14.38
|
0.27
|
|
2000
|
248
|
117
|
127
|
41.31
|
5.87
|
41.35
|
15.45
|
0.42
|
|
1993-2000
|
1904
|
933
|
935
|
40.06
|
3.89
|
41.13
|
14.11
|
0.25
|
Table 4 Wagers Based on Cumulative Points
|
Pointspread
|
Total Line
|
|||||
|
Bets
|
Won (%)
|
Dollars (%)
|
Bets
|
Won (%)
|
Dollars (%)
|
|
|
1993
|
204
|
48.53
|
10.04
|
205
|
51.71
|
-3.63
|
|
1994
|
205
|
56.59
|
34.55
|
206
|
51.94
|
13.31
|
|
1995
|
223
|
56.50
|
41.01
|
216
|
50.93
|
9.98
|
|
1996
|
223
|
50.22
|
1.70
|
219
|
50.23
|
-26.30
|
|
1997
|
214
|
53.27
|
-0.03
|
222
|
56.76
|
30.82
|
|
1998
|
213
|
49.77
|
-27.07
|
222
|
45.95
|
-23.75
|
|
1999
|
225
|
53.33
|
-4.46
|
225
|
52.44
|
17.74
|
|
2000
|
226
|
48.23
|
-10.16
|
227
|
44.49
|
-19.24
|
|
1993-2000
|
1733
|
52.05
|
3.73
|
1742
|
50.52
|
-2.24
|
Table 5 Wagers Based on Cumulative Games
|
Pointspread
|
Total Line
|
|||||
|
Bets
|
Won (%)
|
Dollars (%)
|
Bets
|
Won (%)
|
Dollars (%)
|
|
|
1993
|
174
|
52.30
|
7.23
|
171
|
53.80
|
9.48
|
|
1994
|
168
|
54.17
|
1.75
|
158
|
56.96
|
10.15
|
|
1995
|
181
|
56.91
|
32.15
|
177
|
57.06
|
23.46
|
|
1996
|
171
|
53.22
|
8.40
|
190
|
46.84
|
-20.07
|
|
1997
|
184
|
51.09
|
9.55
|
181
|
55.25
|
21.89
|
|
1998
|
188
|
51.06
|
-9.40
|
182
|
48.35
|
-19.16
|
|
1999
|
189
|
48.68
|
-11.97
|
189
|
57.14
|
44.55
|
|
2000
|
190
|
55.79
|
18.78
|
203
|
51.72
|
-6.79
|
|
1993-2000
|
1445
|
52.87
|
5.96
|
1451
|
53.27
|
4.25
|
Table 6 Using Cumulative Points with a Cutoff
|
Pointspread
|
Total Line
|
|||||||
|
Bets
|
Won (%)
|
P Value
|
Dollars (%)
|
Bets
|
Won (%)
|
P Value
|
Dollars (%)
|
|
|
0
|
1733
|
52.05
|
.0463
|
3.73
|
1742
|
50.52
|
.3419
|
-2.24
|
|
2
|
1671
|
52.18
|
.0391
|
3.74
|
1699
|
50.97
|
.2188
|
-2.15
|
|
4
|
1614
|
52.17
|
.0429
|
3.79
|
1640
|
51.22
|
.1678
|
-2.08
|
|
6
|
1560
|
52.18
|
.0449
|
3.71
|
1573
|
51.30
|
.1566
|
-1.78
|
|
8
|
1502
|
52.60
|
.0235
|
4.15
|
1492
|
51.27
|
.1691
|
-1.71
|
|
10
|
1426
|
52.31
|
.0426
|
4.15
|
1434
|
51.74
|
.0978
|
-0.86
|
Table 7 Using Cumulative Games with a Cutoff
|
Pointspread
|
Total Line
|
|||||||
|
Bets
|
Won (%)
|
P Value
|
Dollars (%)
|
Bets
|
Won (%)
|
P Value
|
Dollars (%)
|
|
|
0
|
1445
|
52.87
|
.0155
|
5.96
|
1451
|
53.27
|
.0068
|
4.25
|
|
2
|
1199
|
52.79
|
.0283
|
6.09
|
1235
|
53.93
|
.0031
|
4.98
|
|
4
|
563
|
53.46
|
.0546
|
9.63
|
604
|
52.15
|
.1545
|
1.51
|
|
6
|
228
|
57.02
|
.0199
|
22.47
|
260
|
54.23
|
.0963
|
8.45
|
|
8
|
79
|
58.23
|
.0883
|
31.91
|
109
|
54.13
|
.2218
|
9.89
|
|
10
|
19
|
73.68
|
.0318
|
152.53
|
40
|
57.50
|
.2148
|
23.52
|
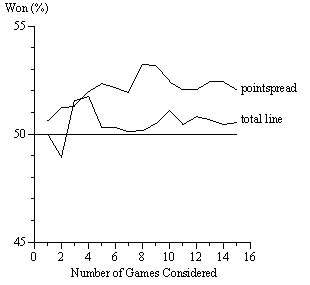
Figure 1. Using cumulative points with different horizons
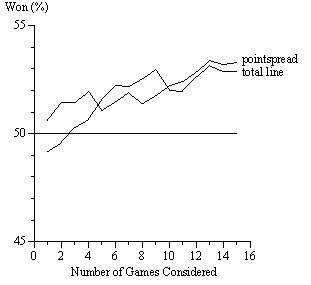
Figure 2. Using cumulative games with different horizons