Statistics for Liberal Arts Students
Gary Smith
Pomona College
Pomona College’s general education program requires every student to take
at least one course in each of ten skill areas, three of which are of interest
here. Use and understand the scientific method involves understanding and being
able to practice the methods used by scientists to understand the natural world;
it can be satisfied by a science course that has an experimental laboratory
component. Use and under-stand formal reasoning involves the development of
abstract reasoning skills; it can be satisfied by a calculus course, a philosophy
course teaching formal logic, or other courses that use formal reasoning to
deduce the logical consequences of well-defined assumptions or axioms. Understand
and analyze data involves an understanding of how analytical and graphical techniques
can be employed to summarize, display, and analyze data; it can be satisfied
by a statistics course.
The development and implementation of this program had the beneficial effect of separating statistics from mathematics. Previously, we had a quantitative requirement that could be satisfied by a course in either mathematics or statistics. Some faculty argued that statistics is just a “subfield of mathematics” and consequently not important enough to have its own skill category. While statistics does use mathematical symbols and proofs, so do many other disciplines including economics, engineering, and physics. These disciplines also use words, but that does not make them subfields of English. Ultimately, the faculty decided that statistical reasoning is not just a branch of mathematics.
A second benefit of our general education reform is that it forced us to think seriously about the objectives of a statistics course that will be taken by every single student at the college. One daunting challenge was the widespread perception succinctly stated by Hogg (1991): “students frequently view statistics as the worst course taken in college.”
In many disciplines, introductory courses pose big questions and provide logical answers that students can grasp and, more importantly, retain without the use of sophisticated tools. Advanced courses examine the fine detail behind these answers and provide increasingly complex and subtle answers using ever more powerful techniques.
There are many advantages to this approach—from the rough to the fine, from the coarse to the subtle, from the intuitive to the rigorous. One is that students who will never take another course in the discipline have an opportunity to learn some powerful principles that they can use throughout their lives. A second advantage is that students can be more easily persuaded that these concepts are powerful and useful.
It is sometimes argued that students who will go on to become professional statisticians should take a very different kind of introductory course. It is certainly true that professional statisticians should at some point take mathematically rigorous statistics courses. However, they too can benefit from an introductory course that emphasizes the application of statistical reasoning and procedures. Math in a vacuum can be misapplied. In addition, an introductory statistics course that shows the practical application of statistical reasoning may be just what is need to persuade the mathematically inclined that statistics is a worthwhile career. James Tobin (1985), a Nobel laureate in economics, wrote of how introductory economics courses lured him into becoming a professional economist: “the subject was and is intellectually fascinating and challenging; at the same time it offered the hope that improved understanding could better the lot of mankind.” Wouldn’t it be wonderful if we could say the same of introductory statistics courses.
Some argue that the way to reform introductory statistics courses is to emphasize data analysis rather than mathematical technique (e.g., Bradstreet 1996; Cobb 1991; Hogg 1991); others argue that hands-on activities should replace passively received lectures (e.g., Fillebrown 1994; Gnanadesikan 1997; Ledolter 1995; Snee 1993). No single course will fit all; instead, each instructor should think seriously about the course’s long-run objectives.
Most liberal arts students will be consumers of statistics, rather than producers. An introductory statistics course that is useful and memorable should prepare them for how they will encounter statistics in their careers and daily lives. Just as a liberal arts education should prepare them to evaluate logical arguments critically, so should it prepare them to evaluate empirical evidence critically.
The central question is What do we want to give our students in this one course, which may be their only opportunity to develop their statistical reasoning, that they will find useful long after the course is over? Surely not mathematical proofs, memorized formulas, and numerical computations. The most important lessons that students will take away from a statistics course will enable them to distinguish between valid and fallacious statistical reasoning.
Each of us can make up a list of important statistical concepts that should be familiar to every educated citizen. Here is my top-10 list, not in order of importance. This is not a syllabus, but instead a list of ideas that I would like my students to remember after the final exam. Most are obvious candidates and self-explanatory. I will try to justify those that are not.
1. Graphs: good, bad, and ugly Graphs can be used to summarize data and to reveal tendencies, variation, outliers, trends, patterns, and correlations. Useful graphs display data accurately and fairly, don’t distort the data’s implications, and encourage the reader to think about the data rather than the artwork. Because visual displays are intended to communicate information, it is not surprising that they, like other forms of communication, can also be used to distort and mislead. Whether using words or graphs, the uninformed can make mistakes and the unscrupulous can lie. Educated citizens can recognize these errors and distortions.
2. The power of good data Seemingly small samples can yield reliable inferences; seemingly large samples can yield worthless conclusions. It is important to understand the variation that is inherent in sampling (and how a margin for sampling error can be used to gauge this variation) and to recognize the pitfalls that cause samples to be biased.
A particularly widespread problem is the reliance on data from self-selected samples. A petition urging schools to offer and students to take Latin noted that, “Latin students score 150 points higher on the verbal section of the SAT than their non-Latin peers.” A psychology professor concluded that drunk-driving accidents could be reduced by banning beer pitchers in bars; his evidence was that people who bought pitchers of beer drank more beer than did people who bought beer by the bottle or glass. A study found that people who take driver-training courses had more accidents than people who had not taken such courses, suggesting that driver-training courses make people worse drivers. A Harvard study of incoming students found that students who had taken SAT preparation courses scored an average of 63 points lower on the SAT than did freshmen who had not taken such courses (1271 versus 1334). Harvard’s admissions director presented these results at a regional meeting of the College Board, suggesting that such courses are ineffective and that “the coaching industry is playing on parental uncertainty” (The New York Times, 1988). A survey sponsored by American Express and the French tourist office found that most visitors to France do not consider the French to be especially unfriendly; the sample consisted of 1000 Americans who had traveled to France for pleasure more than once during the preceding two years.
3. Confounding effects In assessing statistical evidence, we should be alert for potential confounding factors that may have influenced the results. A 1971 study found that people who drink lots of coffee have bladder cancer more often than do people who don’t drink coffee. However, people who drink lots of coffee are also more likely to smoke cigarettes. In 1993, a rigorous analysis of 35 studies concluded that there is “no evidence of an increase in risk [of lower urinary tract] cancer in men or women after adjustment for the effects of cigarette smoking” (Viscoli, Lachs, and Horowitz, 1993).
4. Using probabilities to quantify uncertainty Probabilities clarify and communicate information about uncertain situations. Confidence intervals and p values clearly require probabilities. So does a useful assessment of any uncertain situation. Whenever we make assumptions that may be wrong, we can use sensitivity analysis to assess the importance of these assumptions and use probabilities to communicate our beliefs about the relative likelihood of these scenarios.
While it is not essential that students learn counting rules and other formulas that can be used to determine probabilities, they should be able to interpret probabilities and to recognize the value of using numerical probabilities in place of vague words. A memorable classroom exercise is to ask students to write down the numerical probability they would assign to a medical diagnosis that a person is “likely” to have a specified disease. The answers will vary considerably. When sixteen doctors were asked this question, the probabilities ranged from 20 percent to 95 percent (Bryant and Norman, 1980). If the word “likely” is used by one doctor uses to mean 20 percent and by another to mean 95 percent, then it is better to state the probability than to risk a disastrous misinterpretation of ambiguous words.
5. Conditional probabilities. Many people do not understand to difference between P[A | B] and P[B | A]. Moore (1982) has argued that conditional probabilities are too subtle and difficult for students to grasp. I think that they are too important to neglect.
The application of contingency tables to an important issue can demonstrate conditional probabilities in a memorable way. One example is this hypothetical question that was asked of 100 doctors (Eddy, 1982): In a routine examination, you find a lump in a female patient’s breast. In your experience, only 1 out of 100 such lumps turns out to be malignant, but, to be safe, you order a mammogram X-ray. If the lump is malignant, there is a 0.80 probability that the mammogram will identify it as malignant; if the lump is benign, there is a 0.90 probability that the mammogram will identify it as benign. In this particular case, the mammogram identifies the lump as malignant. In light of these mammogram results, what is your estimate of the probability that this lump is malignant?
Of the 100 doctors surveyed, 95 gave probabilities of around 75 percent. However, the correct probability is only 7.5 percent, as shown by the following two-way classification of 1000 patients:
|
Test Positive
|
Test Negative
|
Total
|
|
| Lump is malignant |
8
|
2
|
10
|
| Lump is benign |
99
|
891
|
990
|
| Total |
107
|
893
|
1000
|
Looking horizontally across the first numerical row, we see that when there is a malignant tumor, there is an 80 percent chance that it will be correctly diagnosed; however, looking vertically down the first numerical column, we see that of the 107 patients with positive test results, only 7.5 percent actually have malignant tumors: 8/107 = 0.075.
According to the person who conducted this survey, “The erring physicians usually report that they assumed that the probability of cancer given that the patient has a positive X-ray...was approximately equal to the the probability of a positive X-ray in a patient with cancer.....The latter probability is the one measured in clinical research programs and is very familiar, but it is the former probability that is needed for clinical decision making. It seems that many if not most physicians confuse the two.”
The solution is not for doctors and patients to stop using conditional probabilities, but to become better informed about their meaning and interpretation.
The popular press often confuses conditional probabilities. A Denver newspaper concluded that women are better drivers than men because more than half of the drivers involved in accidents are male. Los Angeles removed half of its 4,000 mid-block crosswalks and Santa Barbara phased out 95 percent of its crosswalks after a study by San Diego’s Public Works Department found that two-thirds of all accidents involving pedestrians took place in painted crosswalks. Researchers concluded that anger increases the risk of a heart attack because interviews with 1623 heart-attack victims found that 36 persons reported being angry during the two hours preceding the attack compared to only 9 who reported being angry during the day before the attack. The National Society of Professional Engineers promoted their national junior-high-school math contest with this unanswerable question: “According to the Elvis Institute, 45% of Elvis sightings are made west of the Mississippi, and 63% of sightings are made after 2 p.m. What are the odds of spotting Elvis east of the Mississippi before 2 p.m.?”
6. Law of averages The law of large numbers states that as the number of binomial trials increases, it is increasingly likely that the success proportion x/n will be close to the probability of success p. Too often, this is misinterpreted as a fallacious law of averages stating that in the long run the number of successes must be exactly equal to its expected value (x = pn) and, therefore, any deficit or surplus of successes in the short-run must soon be balanced out by an offsetting surplus or deficit. A gambler said that, “Mathematical probability is going to give you roughly 500 heads in 1000 flips, so that if you get ten tails in a row, there’s going to be a heavy preponderance of heads somewhere along the line” (McQuaid, 1971). Edgar Allan Poe (1842) argued that “sixes having been thrown twice in succession by a player at dice, is sufficient cause for betting the largest odds that sixes will not be thrown in the third attempt.” Explaining why he was driving to a judicial conference in South Dakota, the Chief Justice of the West Virginia State Supreme Court said that, “I’ve flown a lot in my life. I’ve used my statistical miles. I don’t fly except when there is no viable alternative” (Charlotte, West Virginia, Gazette, July 29, 1987).
The sports pages are a fertile source of law-of-averages fallacies. After a Penn State kicker miss three field goals and an extra point in an early-season football game, the television commentator said that Joe Paterno, the Penn State coach, should be happy about those misses because every kicker is going to miss some over the course of the season and it is good to get these misses “out of the way” early in the year. At the midpoint of the 1991 Cape Cod League baseball season, Chatham was in first place with a record of 18 wins, 10 losses. The Brewster coach, whose team had a record of 14 wins and 14 losses, said that his team was in a better position that Chatham: “If you’re winning right now, you should be worried. Every team goes through slumps and streaks. It’s good that we’re getting [our slump] out of the way right now” (Molloy, 1991).
A sports article in The Wall Street Journal on the 1990 World Series ended this way: “keep this in mind for future reference: The Reds have won nine straight World Series games dating from 1975. Obviously, they’re heading for a fall” (Klein 1990). In March of 1992, the Journal reported that, “Foreign stocks--and foreign-stock mutual funds—have been miserable performers since early 1989, which suggests a rebound is long overdue” (Clements, 1992). Four months later, the Journal repeated its error, this time reporting ominously that the average annual returns over the preceding ten years on stocks, long-term Treasury bonds, and Treasury bills had all been above the average annual returns since 1926. Their conclusion: “after years of above-average returns, many investment specialists say the broad implication is clear: They look for returns to sink well below the average” (Asinoff 1992).
7. A hypothesis test is a proof by statistical contradiction If students don’t understand conditional probabilities, they won’t understand p values. They should understand both. It is especially important to recognize that the failure to reject a null hypothesis doesn’t prove the null hypothesis to be true. Two economists studying the effect of inflation on election outcomes estimated that the inflation issue increased the Republican vote in the 1976 election by 7 percentage points, plus or minus 10 percentage points. Because 0 is inside this interval, they concluded that, “in fact, and contrary to widely held views, inflation has no impact on voting behavior” (Arcelus and Meltzer, 1977).
8. The difference between statistical significance and practical importance. The 1971-1972 Toronto tests of Linus Pauling’s claim that large doses of vitamin C help prevent colds found that 26 percent of those taking megadoses of vitamin C were cold-free, compared to 18 percent of those taking the placebo; the two-sided p value was 0.0064. One question is whether the difference between 26 and 18 percent is substantial; a separate question is whether the 0.0064 p value is statistically persuasive. (To clarify this distinction, I often say statistically persuasive instead of statistically significant.) Ninety percent of males and 92 percent of females are right handed; this difference is statistically persuasive, but generally unimportant. Willard H. Longcor, a man with clearly too much free time, rolled inexpensive dice 1,160,000 times and found that 0.50725 of the rolls were even numbers, giving a z value of 15.62 (Mosteller, Rourke, and Thomas, 1961).
9. Correlation is not causation. We should not be impressed with low, even spectacularly low, p values unless there is also a logical explanation, and we should be particularly skeptical when there has been data mining. A fun example is the remarkable correlation between the Super Bowl and the stock market: when the winning team is in the NFC or had been in the pre-merger NFL, the stock market has usually gone up. Other cases can be more subtle. Data from six large medical studies found that people with low cholesterol levels were more likely to die eventually of colon cancer; however, a later study indicated that the low cholesterol levels may have been caused by colon cancer that was in its early stages and therefore undetected. For centuries, residents of New Hebrides believed that body lice made a person healthy. This folk wisdom was based on the observation that healthy people often had lice and unhealthy people usually did not. It was not the absence of lice that made people unhealthy, but the fact that unhealthy people often had fevers, which drove the lice away. There was a reported positive correlation between stork nests and human births in northwestern Europe, though few believe that storks bring babies. Storks like to build their nests on buildings: where there are more people, there are usually more human births and also more buildings for storks to build nests.
A particularly common source of coincidental correlations is that many variables are related to the size of the population and tend to increase over time as the population grows. If we pick two such variables at random, they may appear to be highly correlated, when in fact they are both affected by a common omitted factor--the growth of the population. With only a small amount of data mining, I found a 0.91 R2 and 6.4 t value using annual data on the number of U.S. golfers and the nation’s total number of missed work days due to reported injury or illness--every additional golfer leads to another 12.6 missed days of work (Smith, 1998). It is semi-plausible that people may call in sick in order to play golf (or that playing golf may cause injuries). However, most workers are not golfers and most missed days are not spent playing golf or recovering from golf. The number of golfers and the number of missed days have both increased over time, not because one was causing the other, but because both were growing with the population. If we convert the data to per capita values, the coincidental correlation disappears (R2 = 0.04 and t = 0.39).
Another memorable correlation is between the total number of marriages in the United States and the total amount of beer consumed. Does drinking lead to marriage, or does marriage lead to drinking?
10. Regression toward the mean. Regression toward the mean occurs when real phenomena are measured imperfectly, causing extreme measurements to exaggerate differences among the underlying phenomena. Francis Galton observed regression toward the mean in his seminal study of the relationship between the heights of parents and their adult children (Galton, 1886). Among the genes passed from parents to children are those that help determine the child’s height. Because heights also depend on diet, exercise, and other environmental factors, observed heights are an imperfect measure of the genetic influences that we inherit from our parents and pass on to our children.
A person who is 6-feet, 6-inches tall might have a somewhat shorter genetically predicted height and experienced positive environmental influences or might have a somewhat taller genetic height and had negative environmental factors. The former is more likely, simply because there are many more people with genetically predicted heights less than 6-feet, 6-inches than with genetic heights more than 6-feet, 6-inches. Thus the observed heights of very tall parents are usually an overstatement of the genetically expected heights of their children.
This statistical pattern does not imply that we will soon all be 5-feet, 8-inches tall! As long as the variation in the underlying gene pool doesn’t change, there will always be unusually tall and unusually short people. Regression toward the mean occurs because heights are influenced by environmental factors too, and those who are unusually tall most likely had positive environmental influences that caused their observed height to be above their genetically inherited height--making them taller than both their parents and their children. A regression-toward-the mean fallacy is to assume that the heights of extremely tall parents are an unbiased estimate of their genetic height and thus an unbiased prediction of the heights of their children.
Regression toward the mean is often seen in sports. As of 1998, there had been 32 Super Bowls in professional football with only 6 teams able to win twice in a row. No professional basketball team repeated as champion between 1969 (the Boston Celtics) and 1988 (the Los Angeles Lakers). In baseball, of the 33 world champions from 1964 through 1997, only 4 repeated. These data are not persuasive evidence that champions become complacent after winning or overweight from excessive celebration, but may instead simply reflect regression toward the mean.
Because observed performance is an imperfect measure of skill, teams that do unusually well are more likely to have experienced good luck than bad--having few injuries and being the beneficiary of lucky breaks and questionable officiating. Few teams are so far superior to their opponents that they can win a championship in an off year. Thus the performance of most champions exaggerates their skill. Because good luck cannot be counted on to repeat, most champions regress to the mean.
The same is true of individual players. Regression toward the mean can explain such cliches as the Cy Young jinx, sophomore slump, rookie-of-the-year jinx, and the Sports Illustrated cover jinx. Everyone has good and bad years, and it would be extraordinary for a player to be the best in the sport while having an off year. Most players who do much better than their peers are also performing better than their own career averages.
A book published in the 1930s had the provocative title The Triumph of Mediocrity in Business. The author discovered that businesses with exceptional profits in any given year tend to have smaller profits the following year, while firms with very low profits generally do somewhat better the next year. From this evidence, he concluded that strong companies were getting weaker, and the weak stronger, so that soon all will be mediocre. This book was favorably reviewed by the president of the American Statistical Association!
The author’s fallacy is now obvious, yet a current best-selling investments textbook by a Nobel laureate makes this same error (Sharpe, 1985). The author discusses a model of stock prices that assumes “economic forces will force the convergence of the profitability and growth rates of different firms.” To support this assumption, he looked at the 20 percent of firms with the highest profit rates in 1966 and the 20 percent with the lowest profit rates. Fourteen years later, in 1980, the profit rates of both groups are more nearly average: “convergence toward an overall mean is apparent....the phenomenon is undoubtedly real.” The phenomenon is regression towards the mean, and the explanation may be statistical, not economic.
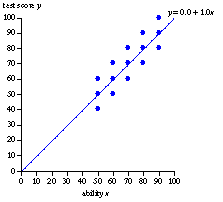
Regression toward the mean explains the success of contrarian investment strategies and why the grass is always greener on the other side of the fence. One memorable way to demonstrate regression toward the mean is with hypothetical data such as these on fifteen students’ abilities and test scores:
|
ability x
|
test score y
|
|
90
|
100
|
|
90
|
90
|
|
90
|
80
|
|
80
|
90
|
|
80
|
80
|
|
80
|
70
|
|
70
|
80
|
|
70
|
70
|
|
70
|
60
|
|
60
|
70
|
|
60
|
60
|
|
60
|
50
|
|
50
|
60
|
|
50
|
50
|
|
50
|
40
|
We can think of ability as what the student’s average score would be on a large number of tests. For convenience, I assume a simple uniform distribution. These test scores are what might be observed on a single test. For any value of ability, the average value of the test scores is equal to ability. The least squares lines for predicting test scores from ability is y = x:
Now, look what happens when we reverse the axes and use test scores to predict abilities:
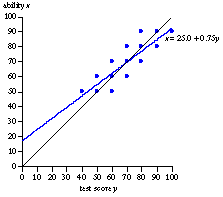
For above-average test scores, the average value of abilities is less than the test score; for below-average test scores, the average value of abilities is larger than the test score. The least squares line that predicts abilities best is x = 25.0 + 0.75y. A student who scores 10 points above (or below) average is predicted to have an ability that is 7.5 points above (or below) average
Looking horizontally, at every level of ability, test scores are symmetrically scattered about ability. Looking vertically, however, relatively high test scores are more likely to be unusually good scores by persons of more modest ability than to be unusually poor scores by persons of extraordinary ability. On average, high test scores overstate ability. To predict ability more accurately, we have to shrink the test scores toward their mean. The highest scorers on this test will, on average, not do as well on the next test (Smith, 1997).
References ]Arcelus, F., and Meltzer, A. H. (1975). “The Effect of Aggregate Economic Variables on Congressional Elections” American Political Science Review, 69, 232-1239.
Asinoff, L. “Double-Digit Returns May be Tougher to Find,” The Wall Street Journal, July 27, 1992.
Bradstreet, T. E. (1996). “Teaching Introductory Statistics Courses So That Nonstatisticians Experience Statistical Reasoning”, The American Statistician, 50, 1, 69-78.
Bryant, G. D., and Norman, G. R. (1980). “Expressions of Probability: Words and Numbers,” letter to the New England Journal of Medicine, February 14, 1980, 411.
Clements, J. “ďBuy Foreign,’ Strategists Urge U.S. Investors,” The Wall Street Journal, March 3, 1992.
Cobb, G. W. (1991). “Teaching Statistics: More Data, Less Lecturing,” Amstat News, 182, 1 and 4.
Eddy, D. (1982). “Probabilistic Reasoning in Clinical Medicine: Problems and Opportunities,” in D. Kahneman, P. Slovak, and A. Tversky, Judgment Under Uncertainty: Heuristics and Biases, Cambridge, England: Cambridge University Press, 249-267.
Fillebrown, S. (1994). “Using Projects in an Elementary Statistics Course for Non-Science Majors,” Journal of Statistics Education, Vol. 2, No. 2.
Galton, F. (1886). “Regression Towards Mediocrity in Hereditary Stature,” Journal of the Anthropological Institute, 246-263.
Gnanadesikan, M. (1997). “An Activity-Based Statistics Course,” Journal of Statistics Education, Vol. 5, No. 2.
Hogg, R. V. (1991). “Statistical Education: Improvements Are Badly Needed,” The American Statistician, 45 (4), 342-343.
Klein, F. C. “The Reds Beat Fate,” The Wall Street Journal, October 22, 1990.
Ledolter, J. (1995). “Projects in Introductory Statistics Courses,” The American Statistician, 49, 364-367.
McQuaid, C., ed. (1971). Gambler’s Digest, Northfield, Illinois: Digest Books, 287.
Molloy, T. (1991). “Gatemen, Athletics Cape League Picks,” Cape Cod Times, July 19, 1991.
Moore, D. S., (1982). “What is Statistics?,” in Perspectives on Contemporary Statistics, D.C. Hoaglin and D.S. Moore, eds., Washington, D.C.: Mathematical Association of America.
Mosteller, F., Rourke, R. E. K., and Thomas, G. B., Jr. (1961). Probability with Statistical Applications, Reading, Mass.: Addison-Wesley, 17.
The New York Times (1988). “SAT Coaching Disparaged,”, February 10, 1988.
Poe, E. A. (1842). “The Mystery of Marie Roget,” Lady’s Companion.
Sharpe, W. F., (1985). Investments, third edition, Englewood Cliffs, New Jersey: Prentice-Hall, 430.
Smith, G. (1997). “Do Statistics Test Scores Regress Toward the Mean?,” Chance, Winter 1997, 42-45.
Smith, G. (1998), Introduction to Statistical Reasoning, New York, McGraw-Hill.
Snee, R. D. (1993). “What’s Missing in Statistical Education?,” The American Statistician, 47, 149-154.
Tobin, J. (1985). “Forward” for G. Smith, Macroeconomics, New York: W.H. Freeman.
Viscoli, C. M., Lachs, M. S., and Horowitz, R. I. (1993). “Bladder Cancer and Coffee Drinking: A Summary of Case-Control Research,” The Lancet, June 5, 1993, 1432-1437.
![]()